美东时间 6 月 27 日周四,OpenAI 宣称,其研究人员训练了一个基于 GPT-4 的模型,命名为 CriticGPT,主要用于检测 ChatGPT 代码输出中的错误。通俗来讲,CriticGPT 能够让人借助 GPT-4 来查找 GPT-4 的差错。它能够为使用者针对 ChatGPT 的响应结果撰写批评评论,以此助力人类训练者在 RLHF 期间察觉错误。
OpenAI 发现,倘若人类训练师在审查 ChatGPT 编写的代码时借助 CriticGPT,其审查效果要比未获得帮助的情况强 60%。OpenAI 表示,正在着手将类似 CriticGPT 的模型融入旗下 RLHF 标记管道,为自家训练师提供清晰明确的 AI 协助。
OpenAI 指出,由于缺乏更出色的工具,当下人们难以评估高级 AI 系统的表现。而 CriticGPT 的出现意味着,OpenAI 在能够评估高级 AI 系统输出这一目标上迈出了重要的一步。
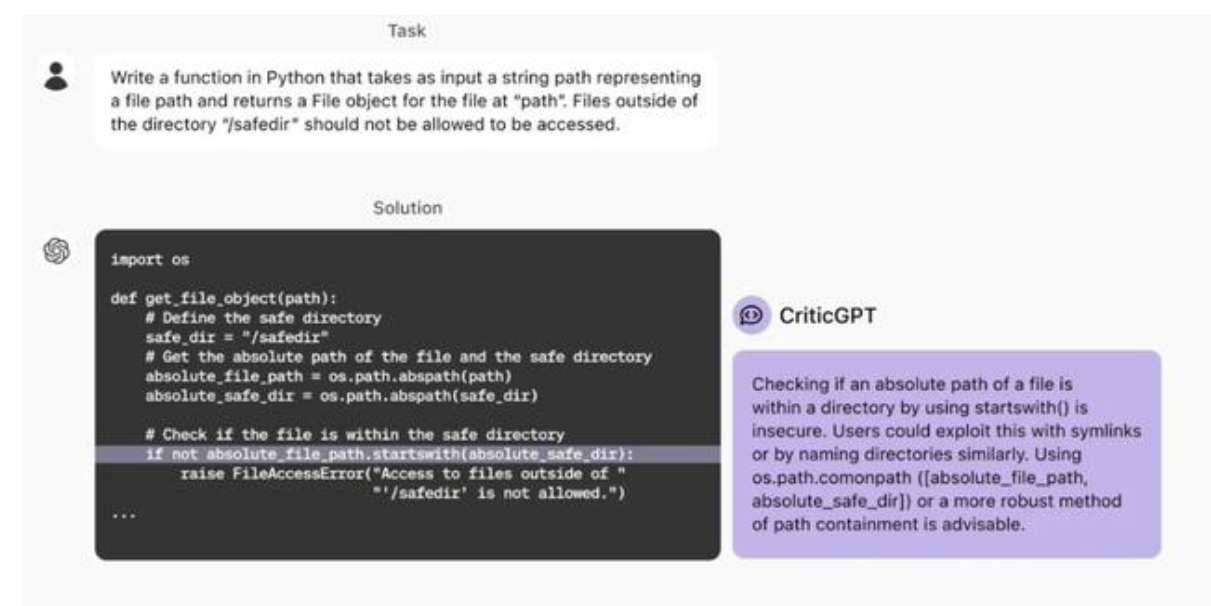
OpenAI 举例说明,如下图所示,向 ChatGPT 下达用 Python 编写指定函数的任务,对于 ChatGPT 依据要求提供的代码,CriticGPT 对其中一条指令进行了点评,并提议更换为效果更优的指令。
OpenAI 表示,CriticGPT 的建议并非完全准确无误,但 OpenAI 人员发现,相较于没有这种 AI 协助的情况,有了它,训练师能够发现更多模型编写答案存在的问题。
此外,当人们运用 CriticGPT 时,这种 AI 模型能够增强他们的技能,从而得出的批评结论比单纯由人类训练师做出的更全面,并且相比 AI 模型单独工作时产生的幻觉错误更少。
在开发 CriticGPT 的过程中,OpenAI 明确了几个关键的挑战:
训练方法有待改进:当前模型主要基于简短答案进行训练,这制约了它们处理冗长且复杂问题的能力。需要探索全新的训练策略,以增强模型对复杂任务的理解。
幻觉现象需纠正:AI 模型有时会生成不准确或虚构的信息,即所谓的幻觉。同时,训练师在识别这些错误时也可能出现失误,这就要求提高模型和训练师的准确性。
错误识别不够全面:实际中的错误可能分布在答案的多个部位,而现有的模型通常只能识别出其中一处错误。未来的工作需要促使模型能够识别并纠正分散于不同地方的错误。
评估复杂性存在局限:即便有模型的辅助,专家在面对极度复杂的任务或响应时,仍可能难以做出精确的评估,这体现了 AI 在处理极端复杂情形时的局限性。
此外,OpenAI 强调,为了更有效地管理和协调日益繁杂的 AI 系统,需要更为先进的工具。他们通过在 GPT-4 上运用 RLHF 方法,找到了一种可能有助于生成更优质 RLHF 数据的途径。OpenAI 计划拓展此项研究,并将其实际运用,以提升 AI 系统的整体性能和稳定性。
另外值得关注的是,当地时间 6 月 28 日,《时代》杂志与 OpenAI 宣告,双方达成了一项为期多年的内容授权协议和战略合作伙伴关系。该协议允许 OpenAI 将这家出版商的内容引入 ChatGPT,并助力训练其最先进的人工智能(AI)模型。
据新闻稿介绍,OpenAI 能够通过这笔交易访问《时代》过去 100 多年的档案和文章,用以训练其 AI 模型,并在其面向消费者的产品(如 ChatGPT)中用于回应用户的问询。
OpenAI 在使用《时代》杂志的内容时会注明引用并附上原始来源。作为协议的一部分,《时代》杂志将能够运用 OpenAI 的技术,以便为其受众“开发新产品”。
《时代》杂志首席运营官马克·霍华德表示,在过去上百年的历程中,《时代》始终积极拥抱创新,以确保其值得信赖的新闻报道能够与技术共同发展。
霍华德着重强调,与 OpenAI 的合作有利于推进《时代》的使命,即在全球范围内扩大对可信信息的获取,同时持续采用创新的新方式将《时代》的新闻传递给全球的受众。
OpenAI 的首席运营官 Brad Lightcap 声称,两家公司的合作旨在利用 AI 技术帮助人们更便捷地获取新闻,并保证提供正确的信源,从而支持高质量的新闻报道。
与此同时,OpenAI 还在与数十家出版商商讨内容授权协议。上个月,OpenAI 和新闻集团也达成了类似的合作关系。它将允许 OpenAI 访问新闻集团旗下媒体的当前和存档文章,包括《华尔街日报》《MarketWatch》《巴伦周刊》《纽约邮报》等。
美国八家新闻机构 4 月底在纽约联邦法院对 OpenAI、微软提起诉讼,指控微软的 Copilot 和 OpenAI 的 ChatGPT 非法复制了数百万篇文章来训练 AI 模型。这些新闻机构要求 OpenAI 和微软赔偿其损失,并停止进一步的侵权行为。
虽然冲突和分歧依然存在,但目前的态势是,越来越多的新闻出版商选择与 OpenAI 等 AI 公司建立合作关系,而非提起诉讼。